📌 1. 해당 주제의 글을 작성하게 된 이유
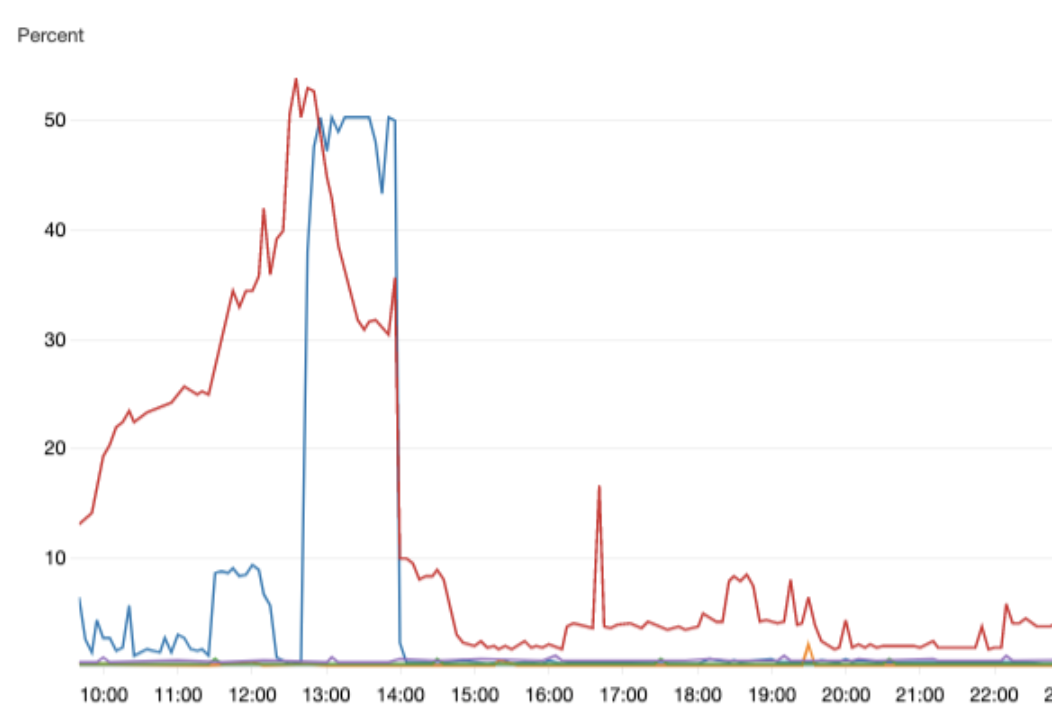
평화로운 평일 늦은 오후, 서비스에 장애가 발생한 것을 인지하였습니다.
서버 프로세스는 종료되지 않았고, API 요청 또한 정상적으로 수신하고 있었습니다. CPU도 여유가 있었구요.

문제를 좀 더 분석하기 위해 프로세스의 로그를 조사해보니, DB 서버 인스턴스와의 연결 중 CLOSE_WAIT 상태에 빠진 클라이언트가 API 응답을 하지 못하고 있었습니다.
서버 인스턴스에는 문제가 없으니, DB 인스턴스에 문제가 있다는 것으로 원인이 좁혀졌습니다.
현재 ‘도기보기’ 서비스에는 MongoDB를 적용하여 운영중이며, 이전 글 에 등장했던 이슈로 인해 관리형 서비스인 Atlas를 이용하고 있는데요, Atlas의 콘솔에서 현재 DB 인스턴스들의 상태를 파악해보니 CPU 점유율이 미친듯이 상승해있는 것을 발견할 수 있었습니다.

우선은 빠른 서비스 정상화를 위해 DB 인스턴스를 두 단계 스케일업하였고, 빠르게 급한 불을 껐습니다.
분위기가 조금은 진정된 후에, 차가운(?) 머리로 해당 현상의 원인을 분석하기 시작했습니다. 클라이언트와 백엔드에서의 최근 배포 내용들을 검토하고, 다같이 머리를 맞댄 결과 현재 운영중인 서비스의 리포트 페이지 내 데이터를 조회하는 특정 쿼리의 복잡도가 높아져 Read/Write 작업에 오버헤드가 발생했다는 결론을 지었습니다.

최종적으로는 해당 쿼리가 실행되는 콜렉션에 index를 적용하여 해결하였는데, 이 과정에서 팀 내부적으로 공유할 겸 MongoDB의 index에 대해서 정리해보고자 합니다.
 쿼리가 사용되는 실제 서비스 내 페이지
쿼리가 사용되는 실제 서비스 내 페이지
📌 2. MongoDB의 index란?
간단히 말하자면 indexing은 빠른 쿼리 실행을 위해 데이터들을 일정 기준에 맞게 미리 정렬해놓는 것을 의미합니다. (공식 다큐먼트)
예를 들어보겠습니다. 한 대학교에서 학생들의 입학 시험의 영어 점수를 높은 순으로 리턴해주는 쿼리가 있고, 특정 날짜의 특정 시간에 학생들에게 시험 점수의 등수를 보여주는 웹페이지가 있다고 생각해봅시다.
우선 시험 성적 collection에는 영어 시험 점수를 저장하고있는 document들이 저장되어있고, 당연히 시험 성적 순서에 상관없이 저장되어있습니다.
 한 칸당 document 하나를 의미함. 시험 성적(score) 값에 상관없이 저장되어있음.
한 칸당 document 하나를 의미함. 시험 성적(score) 값에 상관없이 저장되어있음.
이러한 상황에서, 만약 특정 시간에 한 대학교의 여러 학생들이 본인의 영어 점수의 등수를 알기 위해 동시에 해당 웹페이지를 켠다고 가정해볼까요? DB에서는 해당 쿼리 요청을 받으면 다음의 과정을 수행할 것입니다.
db.student.find({}).sort({score:-1})
(1) 전체 collection 탐색
(2) score 필드의 값들을 가지고 collection을 정렬(ordering)
고등학교의 한 학급도 아니고, 대학교 학생들의 정보를 전부 탐색하고 정렬하는 과정은 결코 양적으로나 복잡도로나 간단하지 않을 겁니다. 쿼리 요청도 동시에 여러개를 수신한다면 DB의 부하는 더해가겠죠?
“학생들의 시험 성적을 매번 탐색/정렬하지 말고, 미리미리 데이터가 추가될 때마다 해당 기준(영어 성적)에 맞게 정렬된 채로 저장해놓으면 되지 않을까요?”
맞습니다. 해당 콜렉션을 조회하고 이용하는 쿼리들의 특성을 모두 고려해야겠지만, 위와같은 상황이라면 학생 collection의 데이터들을 점수 순으로 미리 저장해놓는 장치가 있으면 도움이 될 것입니다. 바로 이러한 장치가 index입니다.
Index
Indexes are special data structures [1] that store a small portion of the collection’s data set in an easy to traverse form. The index stores the value of a specific field or set of fields, ordered by the value of the field. index란 콜렉션 데이터셋의 일부를 traverse하기 편리한 형태로 저장하는 특수한 데이터 구조이다. index는 특정 필드나 필드들의 값을 정렬하여 저장한다.
(추가)
DB를 설계하고 운영하는 입장에서 특정 콜렉션에 indexing을 할 수 있는데, 해당 값을 기준으로 오름차순으로 정렬할지, 내림차순으로 정렬할지 사용자가 결정할 수 있습니다.
다시 앞서 설명한 예시 상황으로 돌아가봅시다.
 파란색 막대가 index를 의미합니다.
파란색 막대가 index를 의미합니다.
콜렉션에 데이터(다큐먼트)가 추가될 때마다 score 필드의 값을 기준으로 index에 데이터가 저장됩니다.
앞서 예시로 든 상황에서, 시험 등수를 요청하는 쿼리 요청이 수신된다면 기존처럼 collection을 탐색하여 정렬하는 것이 아닌, 미리 정렬된 index를 조회하여 데이터를 리턴하면 되니 많은 과정이 생략될 수 있겠죠?
📌 3. 이것들도 알아갑시다
3.1 _id 필드
3.2 다양한 indexing 유형
3.3 index를 여러개 만들면 무조건 좋은거 아닌가요?
index에 대한 개념을 대략적으로라도 이해했다면, 다음의 내용들도 알아가면 좋습니다.
3.1 _id 필드
몽고DB의 콜렉션에는 기본적으로 _id 필드를 기준으로 index가 적용되어있습니다. 그냥 index도 아니고 ‘unique index’ 라고 하는데요,
한 콜렉션 내에 해당 index가 적용된 필드는 같은 value를 갖지 않으므로 같은 콜렉션 내의 다큐먼트들은 서로 다른 _id 값을 가지고 있습니다.
다큐먼트가 생성됨에 따라 MongoDB 자체적으로 자동 생성되는 필드/값이며, 해당 다큐먼트가 생성된 타임스탬프값을 가지고있습니다.
따라서 별도의 indexing이 되어있지 않은 콜렉션은 시간 순서대로 저장되고있다고 생각하면 됩니다.
여담으로, 서비스를 운영하다보면 특정 다큐먼트가 언제 생성되었는지 알고싶을 때가 있는데(예. 고객 문의로 에러 원인 분석시), 이 때 _id값을 통해 생성 시간을 알 수 있겠군요.
참고 : https://www.mongodb.com/docs/manual/reference/bson-types/#objectid
3.2 다양한 indexing 유형
(1) Single index
-
_id필드에 더해 추가적으로 하나의 필드에 index를 더 적용합니다. 위의 예시처럼 score 필드로 indexing하는 상황을 생각해볼 수 있을 것 같습니다.db.collection.createIndex( {score: 1} ) score 기준 오름차순으로 정렬 되었음.
score 기준 오름차순으로 정렬 되었음. -
다큐먼트 내에 임베딩된 다큐먼트 내의 필드에 대해서도 indexing을 할 수 있습니다.
https://www.mongodb.com/docs/manual/core/index-single/#create-an-index-on-an-embedded-field
(2) Compound index
- Single index가 하나의 필드에 indexing하는 것이었다면, compound indexing은 여러 필드에 대한 indexing을 의미합니다.
-
indexing 설정시, 지정해주는 필드의 순서에 주의해야합니다.
db.collection.createIndex( {userid: 1, score: -1} )위의 명령어로 indexing 진행시, index에는 userid로 먼저 정렬하고, 그 안에서 score 순으로 다시 정렬을 진행할 것입니다.

만약 아래와같이 설정했다면 score를 기준으로 먼저 정렬하고, 그 안에서 userid 순으로 다시 정렬했겠죠?
db.collection.createIndex( {score: -1, userid: 1} )덧붙여, MongoDB 공식 문서에서는 다음과 같이 권장하고있습니다. (참고)
- 첫째 우선 순위는 equality 쿼리가 실행되는 필드
- 그 다음 우선 순위는 sort 쿼리가 실행되는 필드
- 마지막 우선 순위는 range 쿼리가 실행되는 필드
참고 : https://www.mongodb.com/blog/post/performance-best-practices-indexing
(3) Multikey index
-
array 타입 데이터를 가진 필드 기준으로 index를 적용하는 것을 의미합니다. array 타입의 값을 가지는 필드로 indexing한 경우, MongoDB에서는 array 내의 모든 데이터들을 기준으로 별도의 index를 생성합니다. 조금 이해하기 어렵죠? 아래 그림을 같이 봅시다.

addr이라는 필드가 zip을 포함한 array 타입의 데이터를 가지고 있습니다. 우리는 해당 필드 내의 zip이라는 필드를 기준으로 indexing하게 되는데요, 이렇게 되면 addr필드 내의 zip 데이터들을 한데 모아 index를 생성합니다. 따라서 array 내의 필드이지만 이 필드를 기준으로 빠른 조회가 가능해지게 됩니다.
참고 : https://www.mongodb.com/docs/manual/core/index-multikey/
(4) Partial index
- 특정 조건의 필드 값을 가진 데이터만 indexing하는 방법입니다.
- (예) boolean 타입의 데이터를 가지는 필드가 있다고 했을 때, true값을 가지는 데이터들만 indexing합니다. 이렇게 되면 true값을 가지는 데이터를 빠르게 조회할 수 있고, 반대로 false인 데이터를 write하는 속도도 해당 필드를 모두 indexing할 경우보다 빠릅니다.
3.3 index를 여러개 만들면 무조건 좋은거 아닌가요?
index 덕분에, 특정 쿼리에서는 모든 document를 탐색할 필요가 없어졌습니다. 또한 서비스를 운영하며 사용되는 쿼리에따라 index를 필요할 때마다 제거(drop)하고 적용할 수 있어서, 민첩하게 쿼리의 성능을 최적화할 수 있습니다.
하지만 아무리 WiredTiger 엔진을 사용하는 MongoDB라고 하더라도, indexing 작업은 인스턴스의 RAM과 디스크 자원을 잡아먹는(?) 작업입니다. 관련된 필드가 업데이트될 때마다, 기존의 index는 유지한 채로 CPU와 I/O의 오버헤드가 발생할 수 있습니다. 복잡한 index 설정은 write(insert, update) 작업을 느리게 할 수도 있구요.
따라서 index를 적용하는 입장에서는 다음과 같은 사항들을 고려해보면 좋을 것 같습니다.
- 현재 우리가 성능적으로 중요하게 생각하는 쿼리는 무엇인가? 해당 쿼리가 탐색할 데이터들이 얼마나 많은가?
- 해당 쿼리에서 이용되는 필드는 무엇인가?
- 해당 필드의 데이터 타입은 무엇인가?
참고 : https://www.mongodb.com/docs/manual/applications/indexes/
📌 4. 글을 마무리 하며
MongoDB의 index란 무엇이며, indexing의 유형 등에 대해 알아보았는데요.
이를 통해 저희 서비스에서는 다음과 같은 개선을 할 수 있었습니다.
(1) 쿼리 응답 속도 개선을 통해 서비스 로딩 시간 단축
(2) DB 서버 인스턴스의 인스턴스 스케일 다운, 비용 최적화
글 초반에 설명한 이슈를 해결하는 과정에서 ‘MongoDB를 이용하게 되거나 이용중이라면 index 개념은 반드시 알아야하고, 적용해야한다’는 말을 다시 한 번 깨달을 수 있었습니다.