
이 글에는 다음과 같은 내용들이 담겨있습니다.
📌 1. 문제 상황 인지
📌 2. 대응 내용
📌 3. 개선사항 적용 및 적용 계획
📌 4. 폭풍이 지나고 난 뒤의 이런 저런 생각들
📌 1. 문제 상황 인지
때는 11월 11일, 여느 날과 같이 평화로운 오전이었다. 새롭게 진행중인 프로젝트에 관한 회의를 진행하던 도중, 이메일을 한 통 받게 되었다.

이전에 서버의 이슈를 감지하기 위해 CloudWatch Alarm을 설정해놨었는데, CPU 사용량이 갑자기 증가했다는 알람이었다.
설상가상으로 CS 채널인 카카오톡 문의센터 챗봇으로 여러 문의가 날아오기 시작했다.


📌 2. 대응 내용
괜히 조급한 마음을 가졌다간 문제도 해결 못하고 패닉에 빠질게 뻔했다. 해결이 조금은 느려지더라도 냉정한 마음으로 현상을 바라보고자 했다.
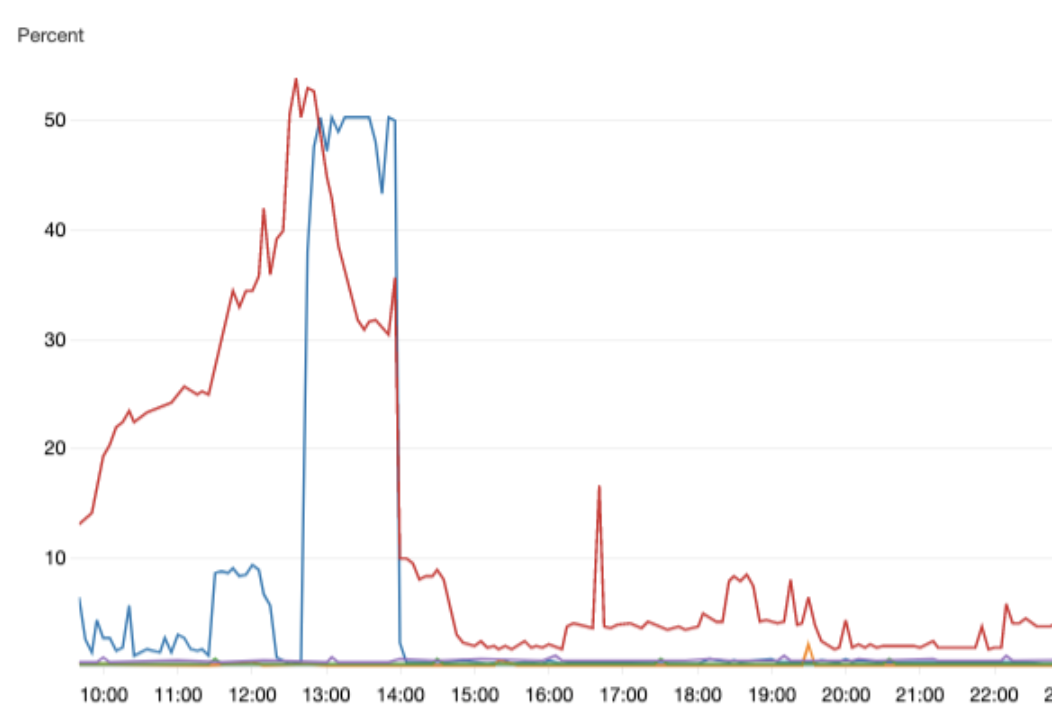
메인 서버에 이슈가 있다고 인지를 했기 때문에, 미리 생성해놓은 CloudWatch 대시보드를 확인했다.
 파란색 그래프는 메인 서버, 빨간색 그래프는 DB 서버
파란색 그래프는 메인 서버, 빨간색 그래프는 DB 서버
두 서버 모두 CPU 이용량이 급증한 상태였고, 실제로 서버가 필요한 모든 기능들의 응답 속도가 느리거나, 작동하지 않는 상태임을 확인했다.
대응 방식은 아래와 같았다.
(1) 관련된 모든 소통을 위한 슬랙 채널 생성
(2) 클라이언트 서비스 내에 서비스 장애 관련 공지
(3) 메인/DB 서버에 영향을 줄 수 있는 모든 애플리케이션 조사
2.1 슬랙 채널 생성
서비스 장애가 발생한 경우, 원인을 파악하여 해결하는 것도 중요하지만 그 외에도 여러 대응이 필요하다고 생각했다. 그렇기 때문에 개발팀 이외에도 관련된 담당자들과의 소통이 필요했고, 이를 위해 급하게 별도의 슬랙 채널을 생성했다.
 그 와중에도 빼빼로데이는 포기하지 못했나봅니다.
그 와중에도 빼빼로데이는 포기하지 못했나봅니다.
해당 채널에서는 서비스 장애 관련 안내 공지 내용이나 푸시 메세지에 들어갈 내용들을 논의하거나, 장애 관련한 이전의 배포, 변경사항들을 공유했다. 장애 해결 이후에는 대응 타임라인과 내용이 채널 내에 그대로 남아있기 때문에 정리하는 데에 많은 도움이 됐다.
2.2 클라이언트 서비스 내에 서비스 장애 관련 공지
서비스 이용에 문제가 생긴 이용자 분들에게 현재 상황을 명확히 공지해야했다. 이용자 입장에서 서버를 거치지 않아도 공지를 확인할 수 있는 곳을 생각해보니 다음과 같았다.
(1) 카카오톡 채널 포스트
(2) 앱 푸시 메세지
(3) CCTV 웹뷰 내의 배너
마음아프고 부끄럽지만, 솔직하게 알리는 것이 중요하다고 생각했다.



2.3 원인 분석 및 대응
장애 공지가 올라가는 동안, 다른 개발자분들과 예상되는 원인에 대한 이야기를 나눴다. 현재 서비스 내의 아키텍처를 간략히 요약하자면 다음과 같다.

위의 아키텍처에서도 알 수 있지만 DB 서버가 통신해야하는 서버가 너무 많았다. 더해서 메인 서버에서도 클라이언트 B와 C를 모두 대응해야하기 때문에 사용자가 몰릴 경우 장애가 발생할 가능성이 없지 않았다(별도로 오토스케일링 설정을 하지는 않았다).
우선은 DB 서버를 조회하는 수를 줄여야했다. 서비스의 기능들 중 우선순위를 고려했을 때, 클라이언트 관련된 기능들(클라이언트 A, B)은 유지하되 클라이언트와 직접적인 관련은 없는 서버 C를 일시 중단하여 상황을 지켜보기로 했다.

다행히도(?) 실제로 DB서버의 부하가 줄어들기 시작했고, 자연스럽게 서비스도 정상화되기 시작했다.
이후로는 조금은 마음을 가라앉히고 마저 중단시킨 서버 C를 정상화 하는 방법, 그리고 이후 백엔드 아키텍처 수정사항을 고민했다.
📌 3. 개선사항 적용 및 적용 계획
이번 서비스 장애를 요약하자면, DB 서버의 연산 처리 시간과 한 번에 많은 요청을 처리할 수 있는 준비가 미흡함으로서 발생한 사태라고 할 수 있다.
어떻게 개선할 수 있을까?
3.1 연산 처리 시간 줄이기
🔧 일부 콜렉션에 인덱스 적용
기존에도 몇 개의 콜렉션에서는 인덱스를 설정하여 조회 속도를 높인 적이 있는데, 이 때의 경험을 가지고 이번 장애와 관련된 서버가 주로 조회하는 콜렉션에도 인덱스를 설정했다. 우리 데이터 기준 20배 정도 속도가 향상된 것을 확인할 수 있었다(find 기준).
🔧 다큐먼트가 너무 많이 쌓인 콜렉션의 데이터 백업 후 삭제
더이상 조회될 일이 없는 데이터가 콜렉션에 불필요하게 남아있다보면 쿼리 수행 시간이 오래 걸릴 수 밖에 없었다. 이러한 데이터들을 따로 백업해놓고(민감하지 않은 정보에 한해) 삭제했다(약 370만 개의 다큐먼트). 당연히 update나 find의 수행 시간을 줄일 수 있었다.
3.2 DB 서버의 스케일 아웃
🔧 샤딩
위와 같은 대응(3.1)을 한다고 하더라도, 결국 시간이 지나 데이터가 많아지게되면 또다시 동일한 현상이 발생할 수 있다. 또한 현재 DB 서버의 하드웨어 성능을 업그레이드 한다고 하더라도, 이를 위한 세팅과 작업 시간 또한 부담이 됐다. 여러 조사 끝에 몽고 DB의 샤딩 구성을 알아보게 됐다.
📌 샤딩이란? - 간단히 말하자면, 데이터를 여러 서버에 분산해서 저장하고 처리하는 기술을 의미한다. 이를 통해 하나의 서버에만 주어졌던 부하를 분산시킬 수 있다. - Replica Set 한 세트를 Cluster라고 칭하며, 이를 여러개 운영할 수 있다.
 몽고DB 샤딩 아키텍처
몽고DB 샤딩 아키텍처
하지만 위의 아키텍처를 운영하기 위해서는 데이터가 어떻게 분산돼있는지에 관한 메타 데이터를 저장하는 Config 서버와 쿼리 요청을 어떤 샤드로 전달할지 결정하는 Router 서버를 추가 구축해야한다. 현재 상황으로서는 이를 구축하는 것도 부담이 되거니와, 서비스를 운영하면서 이를 관리해야하는 리소스(인력) 또한 부담이 됐다. 그러던 중 몽고DB에서 자체적으로 이 모든 것들을 관리형 서비스로 제공하는 Atlas를 알게 되었다.

🔧 DB 서버 마이그레이션(Atlas)
Atlas는 몽고DB를 설계한 사람들이 만들었고, AWS, GCP, Azure와 같은 다양한 클라우드에서 작동하는 관리형 데이터베이스 서비스이다. 실제로 사이트에서 확인해보면 버튼 클릭 몇 번으로 DB 서버를 호스팅 할 수 있으며, 스케일업이나 자동 백업 등 다양한 기능을 제공한다.
 클릭 몇 번으로 샤드 개수도 설정 가능하다
클릭 몇 번으로 샤드 개수도 설정 가능하다
그렇다면 우리의 데이터를 Atlas로 마이그레이션하는 것을 고민해야하는데, 다행히도 Atlas는 Live Migrate(서비스 중단 없이 실시간으로 데이터를 마이그레이션) 기능을 제공한다. 다만 마이그레이션하기 위해서는 다음의 조건이 갖춰져야한다.
- MongoDB Driver 버전을 체크하고, 코드에서 버전에 따른 호환성이 잘 맞는지 체크
- MongoDB가 Replica set으로 배포되었거나 Shard Cluster를 통한 배포인지 체크(만약 하나의 인스턴스에 구축되었다면 우선은 Replica set 구축을 해야한다)
- MongoDB 버전이 2.6 이상인지 체크
- Shard Cluster인 경우 MongoDB 버전이 4.0 이상인지 체크
-
마이그레이션을 할 데이터를 가지고있는 쪽의 User(IAM)는 clusterMonitor, backup 역할(role)을 가지고 있어야한다.
use admin db.getUser("admin") { "_id" : "admin.admin", "user" : "admin", "db" : "admin", "roles" : [ { "role" : "backup", "db" : "admin" }, { "role" : "clusterMonitor", "db" : "admin" } ] } ...
우리의 DB는 다행히도(?) Replica set으로 세팅했기 때문에 마이그레이션을 위한 과정이 복잡하지는 않았다.
데이터를 마이그레이션하는 과정은 추후에 또다른 글에서 정리하고자 한다.
📌 4. 폭풍이 지나고 난 뒤의 이런 저런 생각들
-
항상 부족함을 느낀다. 서비스 개발 초반에 백엔드 개발할 때 좀만 더 공부하고 신경썼다면 어땠을까?하는 후회도 남는다(후회해봤자 소용없지만).
-
추후에 알게된 것이지만, 서비스 장애가 있기 전, 구글 광고 비용을 늘린 것을 알게 되었다. 물론 광고 비용을 늘릴 것이라는 것을 공유받았지만 이렇게 순식간에 트래픽이 늘 것이라고는 생각하지 못했다. 이 부분에 있어 간과한 부분이 있는 것 같고, 마케팅과 개발팀의 소통이 필요한 부분이라고 생각한다.
-
서비스 장애의 과정을 기록하면서, 우리 서비스 개발시 ‘나중에 합시다’하고 넘겼던 개선사항들을 다시 꺼내보게 되었다. ‘언젠간 하겠지’하며 미루던 것들이 이렇게 문제가 생기고서야 알게되는 것들이 후회됐다. 서비스가 점점 더 커질 수록 이런 상황에 의해 잃는 손실이 더 커질텐데, 그런 부분에서 개발을 총괄하는 입장으로서의 책임감을 느끼게 되었다.
-
And more…


